Edge Detection
How To Make Basic Edge Detection Algorithm With C#
Edge detection is a segmentation technique in image processing for extracting object boundaries based on abrupt intensity changes.
Filter by Category
Edge detection is a segmentation technique in image processing for extracting object boundaries based on abrupt intensity changes.
Line detection is a segmentation technique in image processing, with which we can extract thin lines with respect to each filter kernel.
Point detection is a segmentation technique in image processing, we can use to get the position of point objects in the image.
Texture segmentation is a customizable morphological process, with which we can find boundaries between regions based on their texture content
Granulometry is a grayscale morphological operation in image processing for estimating distribution of different sized particles.
Top hat transformation is a grayscale morphological operation in image processing, we can use for extraction of certain objects in the image.
Morphological gradient is a grayscale morphological operation in image processing, which emphasized boundaries and supresses homogenous areas
Morphological smoothing is an image processing technique, which includes grayscale erosion and dilation, and grayscale opening and closing
Automatic algorithm for filling holes is a sequence of morphological operations in reconstruction branch, which fills all holes in the image.
Opening by reconstruction is a morphological operation in image processing for removing small objects and recovering shape accurately after.
Basic edge detection process is a segmentation technique in image processing for extracting boundaries of objects. Furthermore, since we already covered point and line detection, this post will serve as a next step in these processes.
We’re going to cover three groups of filter kernels we can use to accomplish our goal. However, there are still more complex algorithms for edge based segmentation, but we won’t describe them here.
The heart of this algorithm is the use of spatial convolution. In case you’re not familiar with the process, I’ll try to give it to you in a nutshell here.
Convolution is a linear process where we’re placing spatial kernel, a small matrix of predefined values, across the whole image. In order to get the resulting pixel values, we need to multiply values between kernel and pixel data at each location and sum them together.
More precisely, when we multiply all overlaying values, we need to sum them together to the resulting pixel value. After that, we set a new pixel value on the resulting image in the center pixel location of the overlapped neighborhood of pixels.
First of all, there are three steps to this process and it usually begins with image smoothing for noise reduction. Next step is finding all the edge points using multiple filter kernels. And finally, we need to follow a certain criteria to choose from these edge points between these different convolution results.
Important tool for detecting edges is the gradient, which can give us information about their strength and direction. In order to get gradient, we need to compute partial derivatives at every location.
This may seem daunting but don’t worry, there’s a simple solution which doesn’t involve writing any more complicated algorithms.
When we use two filter kernels, one will compute gradient in horizontal direction and the other in vertical direction. Therefore, we can get approximate gradient values by subtracting 1st and 3rd rows for x-direction and columns for y-direction.
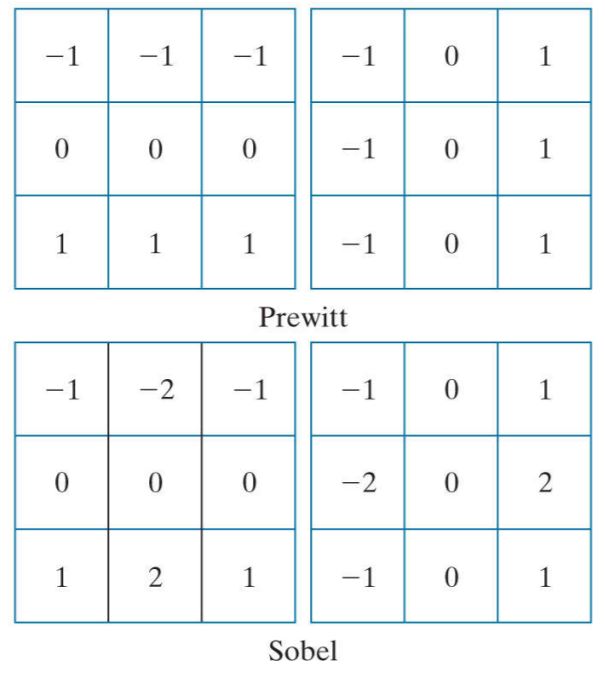
We can get the differences by simply setting negative values in the kernel. There’s a slight difference between Prewitt and Sobel kernel pairs. The reason why Sobel filter kernels have a slightly larger values in the middle is because they produce smoothing.
In order to get the resulting pixel values, we need to compute the magnitude from both gradients. We can do that by calculating the Euclidean distance. However, it involves a lot of computation since we need to do it for every pixel.
A simple optimization for this process is to simply get the sum of their absolute values. This will give us approximate values for magnitude and lessen the strain on computer so it can do it faster.
This process involves using 8 filter kernels, each responsible for detecting edges in one direction. Therefore by using 8 of them, we can detect edge magnitude in all 8 compass directions.
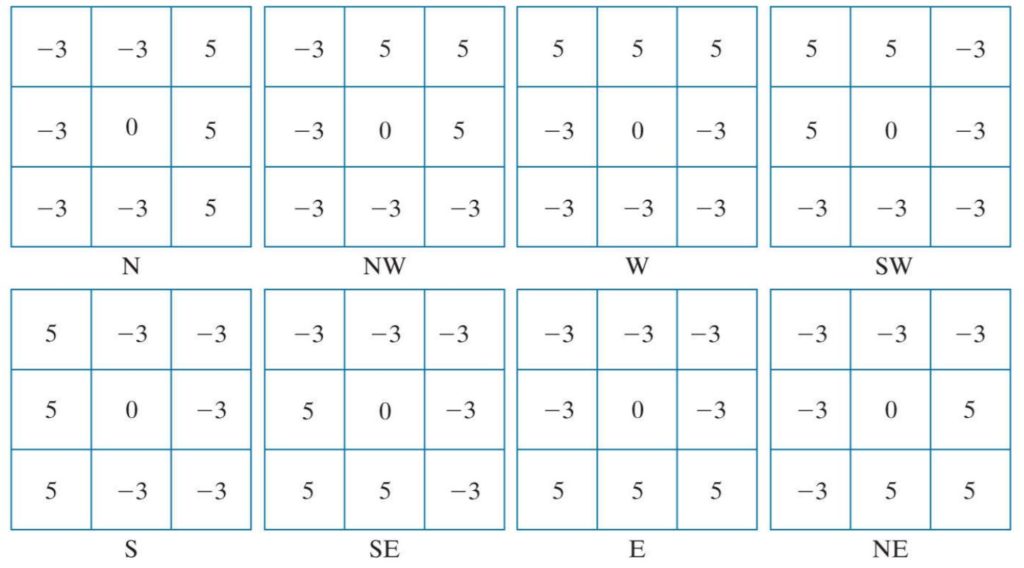
When we’re selecting values among all 8 convolution results, we simply take the largest one from each position. Furthermore, the largest value indicates which compass kernel yielded the largest response, which also tells us the edge direction.
Since convolution results may be negative values, I wrote a function which will return its absolute value. This is important for displaying purposes, since we can only show byte values that range from 0 to 255.
public static byte[] Convolute(this byte[] buffer, BitmapData image_data, int[,] filter)
{
byte[] result = new byte[buffer.Length];
int ho = (filter.GetLength(0) - 1) / 2;
int vo = (filter.GetLength(1) - 1) / 2;
for (int x = ho; x < image_data.Width - ho; x++)
{
for (int y = vo; y < image_data.Height - vo; y++)
{
int position = x * 3 + y * image_data.Stride;
int sum = 0;
for (int i = -ho; i <= ho; i++)
{
for (int j = -vo; j <= vo; j++)
{
int filter_position = position + i * 3 + j * image_data.Stride;
sum += (buffer[filter_position] * filter[i + ho, j + vo]);
}
}
for (int c = 0; c < 3; c++)
{
if (sum > 255)
{
sum = 255;
}
else if (sum < 0)
{
sum = Math.Abs(sum);
}
result[position + c] = (byte)(sum);
}
}
}
return result;
}The following code demonstrates how to detect edges with 2 filter kernels.
public static Bitmap EdgeDetect(this Bitmap image, int[,] kernel1, int[,] kernel2)
{
int w = image.Width;
int h = image.Height;
BitmapData image_data = image.LockBits(
new Rectangle(0, 0, w, h),
ImageLockMode.ReadOnly,
PixelFormat.Format24bppRgb);
int bytes = image_data.Stride * image_data.Height;
byte[] buffer = new byte[bytes];
byte[] temp = new byte[bytes];
byte[] result = new byte[bytes];
Marshal.Copy(image_data.Scan0, buffer, 0, bytes);
image.UnlockBits(image_data);
temp = buffer.Convolute(image_data, kernel1);
result = buffer.Convolute(image_data, kernel2);
for (int i = 0; i < bytes; i++)
{
result[i] = (byte)((result[i] + temp[i]) > 255 ? 255 : (result[i] + temp[i]));
}
Bitmap res_img = new Bitmap(w, h);
BitmapData res_data = res_img.LockBits(
new Rectangle(0, 0, w, h),
ImageLockMode.WriteOnly,
PixelFormat.Format24bppRgb);
Marshal.Copy(result, 0, res_data.Scan0, bytes);
res_img.UnlockBits(res_data);
return res_img;
}And lastly, here’s the code for using Kirsch compass filter kernels.
public static Bitmap KirschCompassEdgeDetect(this Bitmap image)
{
int w = image.Width;
int h = image.Height;
BitmapData image_data = image.LockBits(
new Rectangle(0, 0, w, h),
ImageLockMode.ReadOnly,
PixelFormat.Format24bppRgb);
int bytes = image_data.Stride * image_data.Height;
byte[] buffer = new byte[bytes];
byte[] result = new byte[bytes];
Marshal.Copy(image_data.Scan0, buffer, 0, bytes);
image.UnlockBits(image_data);
int[][,] kernels =
{
Filters.KirschN,
Filters.KirschNE,
Filters.KirschE,
Filters.KirschSE,
Filters.KirschS,
Filters.KirschSW,
Filters.KirschW,
Filters.KirschNW,
};
for (int i = 0; i < kernels.Length; i++)
{
byte[] convoluted = buffer.Convolute(image_data, kernels[i]);
for (int j = 0; j < bytes; j++)
{
result[j] = Math.Max(result[j], convoluted[j]);
}
}
Bitmap res_img = new Bitmap(w, h);
BitmapData res_data = res_img.LockBits(
new Rectangle(0, 0, w, h),
ImageLockMode.WriteOnly,
PixelFormat.Format24bppRgb);
Marshal.Copy(result, 0, res_data.Scan0, bytes);
res_img.UnlockBits(res_data);
return res_img;
}I hope this tutorial was helpful in gaining better understanding on how basic edge detection algorithms work. Furthermore, these processes go well hand in hand with thresholding processes. Reason for this is because sometimes edge detection results tend to get messy.
You can also download the demo project for this tutorial and try it out yourself.